Almost every clinical AI tool is bought on a promise of return: catch deterioration sooner, prevent medication error, shave minutes off a workflow. And almost every one of them delivers that value through the same mechanism, which is an alert. That is where the trouble starts, because alerts have a cost that compounds. Each low-value interruption lowers the odds that the next one gets read, and once clinicians have learned to dismiss a tool on reflex, the return that justified buying it becomes very hard to find. Proving the ROI of clinical AI and controlling the alert burden it creates turns out to be the same problem viewed from two sides.
It helps to be precise about terms, because the search results blur them. Alarm fatigue usually refers to the physiological monitor alarms that surround a hospital bed, the territory of Joint Commission safety goals. Alert fatigue refers to the clickable warnings that fire inside the EHR and clinical decision support, and increasingly from the AI models layered on top of it. This piece is about the second kind, written for the health systems and HIT vendors deploying clinical AI and hoping to show it was worth the spend.
How High Override Rates Affect Patient Safety and Clinical AI ROI
The clearest measure of alert fatigue is how often clinicians ignore the alerts they are shown. The numbers are not subtle. Across health systems, clinicians override between 49% and 96% of drug interaction alerts, with the median for drug-drug interaction warnings sitting around 87%. Studies that review those overrides after the fact tend to find that most were clinically reasonable, because the alert was firing on a known tolerance, a repeated order, or a situation the clinician had already accounted for. The system, in other words, was mostly crying wolf, and the clinicians were mostly right to treat it that way.
The cost of that pattern lands in two places. The first is safety, because a clinician desensitized by a hundred irrelevant warnings is no more likely to catch the one that matters, and the important alert ends up buried among the noise it was supposed to rise above. Response rates have been shown to fall steadily the longer a given alert is in service, as repeated exposure trains the reflex to dismiss. The second cost is the return itself. An alert that is overridden nine times out of ten is not changing care, which means the investment behind it is not producing the outcome it was sold on. Alert volume and alert value pull against each other, and most systems have far more of the former than the latter.
Why Clinical AI Can Increase Alert Fatigues
Layering AI onto this environment can sharpen the problem rather than solve it, because a new model usually means a new stream of alerts, and a model tuned for sensitivity will generate a great many of them. The most instructive case is also one of the most widely deployed. A 2021 external validation of the Epic Sepsis Model, published in JAMA Internal Medicine, found an area under the curve of 0.63, missed roughly two-thirds of the patients who developed sepsis, and still generated alerts on about 18% of all hospitalized patients, which the authors described as a large burden of alert fatigue. A model can underperform on the cases that matter and overwhelm clinicians at the same time.
The reason sits in a tradeoff that no amount of model sophistication removes. Push a model toward catching more true cases, and it fires more often, including on patients who are fine. Tune it down to fire less, and it misses more of the cases it was meant to catch. Where that dial is set, and whether it is set for the local patient population rather than the one the model was trained on, matters more to the lived experience of the tool than its headline accuracy. A strong figure on a vendor slide describes the model in the abstract. What clinicians feel is the number of times a day it interrupts them and how often that interruption was worth having. Deploying a model without tuning its threshold and fitting it to the workflow is a reliable way to manufacture fatigue.
How to Design Clinical AI Alerts That Clinicians Will Act On
Reducing alert fatigue is mostly a design discipline, and it starts from a single principle: an interruption has to earn its place. A few practices carry most of the weight.
Specificity should be favored over raw sensitivity, with thresholds tuned to the population the tool actually serves rather than the one it was built on, and with the clinically insignificant cases filtered out before they ever reach a screen. Alerts should be tiered by what they ask of the clinician, so that an interruptive, work-stopping warning is reserved for the small set of high-acuity, immediately actionable situations, while everything that is useful but not urgent moves into a passive channel such as an inbox, a sidebar, or an order-set nudge that informs without blocking. Redundant and already-handled alerts should be suppressed rather than repeated, since the warning that fires on every refill of a long-tolerated medication is training clinicians to ignore the category. Each alert should reach the person who can act on it at the moment the decision is being made, because an alert sent to the wrong role or the wrong point in the workflow is noise even when it is correct. And the recommended action should be explicit, with a clinician kept in the loop as the decision-maker rather than a rubber stamp.
None of this is a one-time configuration. Alerts behave like a living system, and they need to be governed as one, with periodic review of how often each alert fires, how often it is overridden, and whether it still earns its place. One inpatient study that refined a handful of alerts and retired four of them removed roughly a third of irrelevant firings without losing safety value. Retiring a low-value alert is as much a part of the work as building a good one.
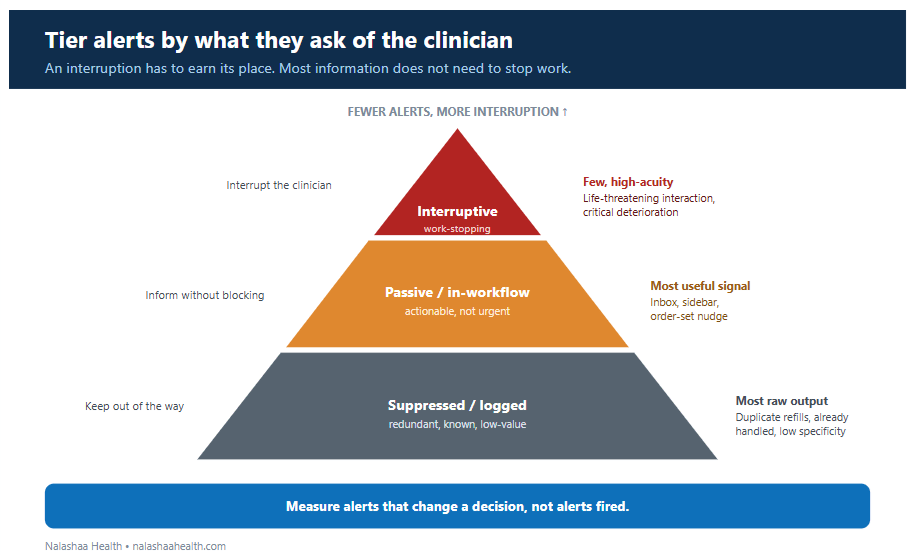
Figure: Tier alerts by what they ask of the clinician. The work-stopping interruption is reserved for the few, high-acuity, immediately actionable cases; most useful information belongs in passive channels; redundant and low-value alerts are suppressed or logged. The guiding measure is alerts that change a decision, not alerts fired.
How to Measure the ROI of Clinical AI Alerts
The metric most dashboards report is the one that means least. Alerts generated, or model accuracy in isolation, say nothing about whether care changed. The honest measure of a clinical AI tool is the count of alerts that altered a decision, and the only way to see it is to track value and burden together rather than one without the other.
On the value side, that means the clinical and operational outcomes the tool was bought to move: conditions caught earlier, adverse events or readmissions avoided, orders changed, time returned to clinicians. On the burden side, it means the cost the tool imposes to produce those gains: alert volume per clinician per shift, override rate, time spent dismissing, and the number of alerts fired for every true positive it surfaces. Net the second against the first, and the real return appears, which is frequently smaller and more specific than the projection in the business case, and far more defensible for it. Part of why ROI so often stays invisible is that few clinical AI tools undergo any economic evaluation alongside their clinical validation, so the financial benefit is never weighed against the workforce cost. Treating return as something to measure in stages rather than declare at launch, an approach we cover in our executive guide to AI and machine learning in healthcare, tends to surface a truer number than a single go-live figure ever will.
Clinical AI Deployment Requirements for Reducing Alert Fatigue
The pattern across all of this is that the model is rarely the deciding factor. Threshold tuning for the local population, workflow-aware routing, alert tiering and suppression, a governance process that reviews and retires alerts, and the measurement scaffolding that connects an alert to an action and an action to an outcome are what separate a clinical AI program that pays back from one that quietly raises the override rate. That work is integration, configuration, and discipline more than data science, and it is where the return is won or lost.
Nalashaa builds and governs clinical AI and decision-support systems for US health systems and HIT vendors, including specificity tuning, EHR-integrated alert design, and the monitoring that keeps both performance and alert burden in view after go-live. Talk to our team about clinical AI that proves its ROI without adding to alert fatigue.
How Alert Design Determines Clinical AI ROI
The return on a clinical AI tool is not set by the model’s accuracy in a paper. It is set by how many clinician decisions the tool actually changes, net of the attention it consumes to do so. That makes alert design and honest measurement the deciding factors, not afterthoughts to a procurement that has already happened. The programs that prove their worth are the ones that treat every interruption as a cost to be justified and every alert as something to be measured by the action it produces.
Nalashaa builds and governs clinical AI and decision-support systems for US health systems and HIT vendors. Talk to our team about reducing alert fatigue while proving the ROI of your clinical AI.
Frequently asked questions
What is alert fatigue? Alert fatigue is the desensitization that sets in when clinicians are exposed to a high volume of alerts, many of them low-value, until they begin overriding or ignoring them by reflex. It matters because the habit of dismissing irrelevant alerts also dulls the response to the rare alert that is clinically important.
What is the difference between alert fatigue and alarm fatigue? Alarm fatigue generally refers to the physiological monitor alarms around a patient’s bedside, such as cardiac and pulse-oximetry alarms. Alert fatigue refers to the clickable warnings generated inside the EHR, clinical decision support, and AI models. They share a mechanism, desensitization through overexposure, but involve different systems and fixes.
How does alert fatigue affect patient safety? When most alerts are irrelevant, clinicians learn to override them quickly, and that reflex carries over to the small number of alerts that signal real danger. High override rates, documented between roughly half and nearly all alerts depending on type, can negate the safety benefit an alerting system was meant to provide.
How do you reduce alert fatigue from clinical AI tools? Tune models for specificity in the local population, tier alerts so only high-acuity actionable cases interrupt the clinician, move the rest into passive channels, suppress redundant alerts, route each alert to the right person at the right moment, and govern the whole set with regular review and retirement of low-value alerts.
How do you measure the ROI of a clinical AI or decision-support tool? Measure the actions it changes, not the alerts it fires. Track clinical and operational value, such as earlier detection, avoided harm, and time saved, against alert burden, such as volume, override rate, and alerts per true positive, and report the net. Staged measurement after deployment gives a more accurate figure than a single launch projection.